Spark RDD 簡介
Spark的核心是 RDD,Resilient Distributed DataSet的縮寫,是一種具有容錯(tolerant)與高效能(efficient)的抽象資料結構。RDD 由一到數個的 partition組成,Spark程式進行運算時,partition會分散在各個節點進行運算,預設會被存放在記憶體內,所以可以快速享各個partition的運算結果,但若記憶體不足會出現OOM Exception錯誤訊息,可透過參數設定存放在硬碟避免發生該錯誤。
RDD支援下列語言撰寫而成的object:
- Scala
- Java
- Python
- R
Spark是由Scala撰寫而成,嚴格遵守Functional Program的概念,所以RDD只能讀取無法寫入。
Spark 支援讀取 HDFS 等分散式儲存裝置的檔案,故可以使用HDFS的特性便於進行分散式的運算。
綜合以上可歸納出RDD具有幾個特性:
- Immutable
- Distributed
- Parallelizing
每個RDD會紀錄五件事情,分成兩種類別:
- i) Lineage
- 1.Set of partitions(“splits” in Hadoop).
- 2.List of dependencies on parent RDDs.
- 3.Function to compute a partition(as an Iterator) given its parent(s).
- ii) Optimized Execution
- 4.(Optional) partitioner (hash, range).
- 5.(Optional) preferred location(s) for each partition.
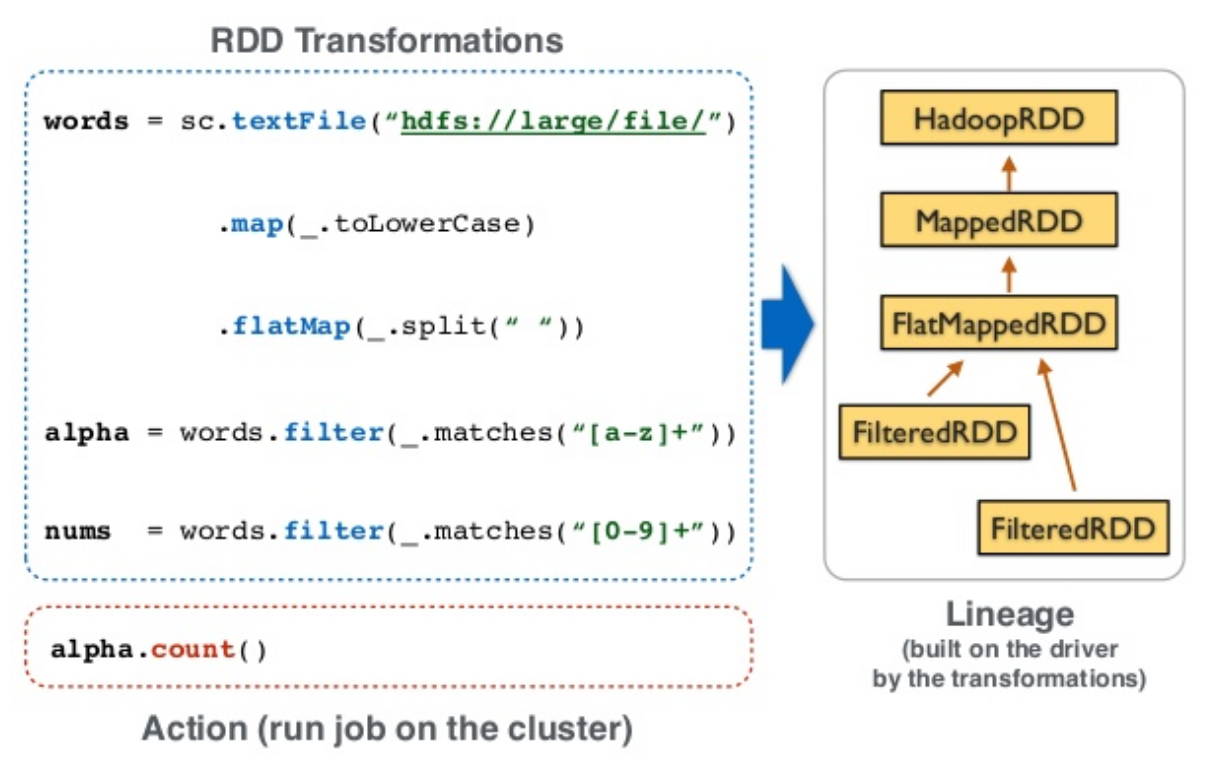
Lineage為RDD的血統關係,主要用來作為容錯處理,先來看一段程式碼:
//RDD Transformations
words = sc.textFile("hdfs://large/file")
.map(_.toLowerCase)
.flatMap(_.split(" "))
alpha = words.filter(_.matches("[a-z]+"))
nums = words.filter(_.matches("[0-9]+"))
//RDD Action
alpha.count()
nums.count()
程式碼內容是讀取HDFS檔案後,轉將內容轉成小寫並且以空白為分割符號將每個字切開,並且以對文字與數字分別進行計算,就是一個wordcount的範例程式。
一個完整的Spark Application一定會有兩大類型的操作:Transformations與Action。
由範例來看words、alpha與nums的操作都屬於Transformations,alpha.count()與nums.count()屬於Action。在RDD中 Transformations 的操作是Lazy運作,亦即不會馬上進行計算,只會紀錄使用到哪些資料集(例如讀取HDFS上某個路徑),當執行Action時才會開始進行運算。當Spark Application的Transformations 數量很多卻又需要重複運作時,可以使用persist(或cache)的method對某個RDD用持久化,這樣該RDD就不會因為Lazy需要重新運算,可以加快運算速度。
查看更多的 transformations API
查看更多的 actions API
由下圖可以看出Wordcount的程式碼轉換成RDD對照與Lineage:
From: https://www.slideshare.net/frodriguezolivera/apache-spark-41601032#44
當某個RDD運作失敗時,Spark會根據Lineage找到parent RDD是誰,並且從parent RDD 繼續計算,以完成整個Spark的運算,由此可以理解Spark的容錯機制。
最後
對Spark RDD有初步的了解後,接下來要來介紹Spark Shell,互動式的操作介面。